

赋予机器东谈主物理领略和预测能力是通用操作的要道。蚂蚁灵波等机构建议的 LingBot-VA 试图将视频帧预测与动作推理调处起来,让机器东谈主通过自追忆扩散框架学会“一边想考一边活动”。
在通用机器东谈主领域,机器东谈主截止需要的不仅仅“看懂”现时画面 ,还需要预测畴昔。若是一个模子不可领略“推倒杯子会导致水洒出来”这种物理因果关联,它就很难在复杂环境中作念出正确研讨。但是,结束妥当的物理推理和预测能力一直是中枢清苦。当机器东谈主靠近需要长程研讨、高精度操作或处理柔性物体的复杂任务时,它们每每显得粗劣且难以妥贴环境的动态变化。
现时主流的视觉-谈话-动作(VLA)模子常常胜仗将视觉不雅察映射到动作,或者依赖于单帧或短时候窗口的预测。但是,这种端到端的范式穷乏显式建模物理过程的机制,导致模子容易堕入轨迹顾虑。同期,将任务视为马尔可夫过程并丢弃历史信息,使得模子在部分可不雅测和长程任务中难以摈斥歧义。此外,现存的视频生成模子常常弃取破损因果关联的双向正经力机制,且推理延长过高,难以得志机器东谈主高频截止的需求。
针对上述问题,来自蚂蚁灵波科技、香港科技大学等机构的询查团队建议了 LingBot-VA,一种全新的自追忆(AR)视频-动作宇宙模子,通过调处视频动态预测和动作推理,将物理宇宙的因果结构融入机器东谈主截止中。该模子不胜仗学习动作散布,而是先预测视觉宇宙将怎么演变,然后基于这些预测推断动作。这种解耦使得模子不错期骗大限制视频数据学习物理先验,同期只需极少机器东谈主演示数据就能将这些先验调养为可施行的动作。
论文招引:
开云app中国2026世界杯官方下载https://arxiv.org/abs/2601.21998
名堂主页:
https://technology.robbyant.com/lingbot-va
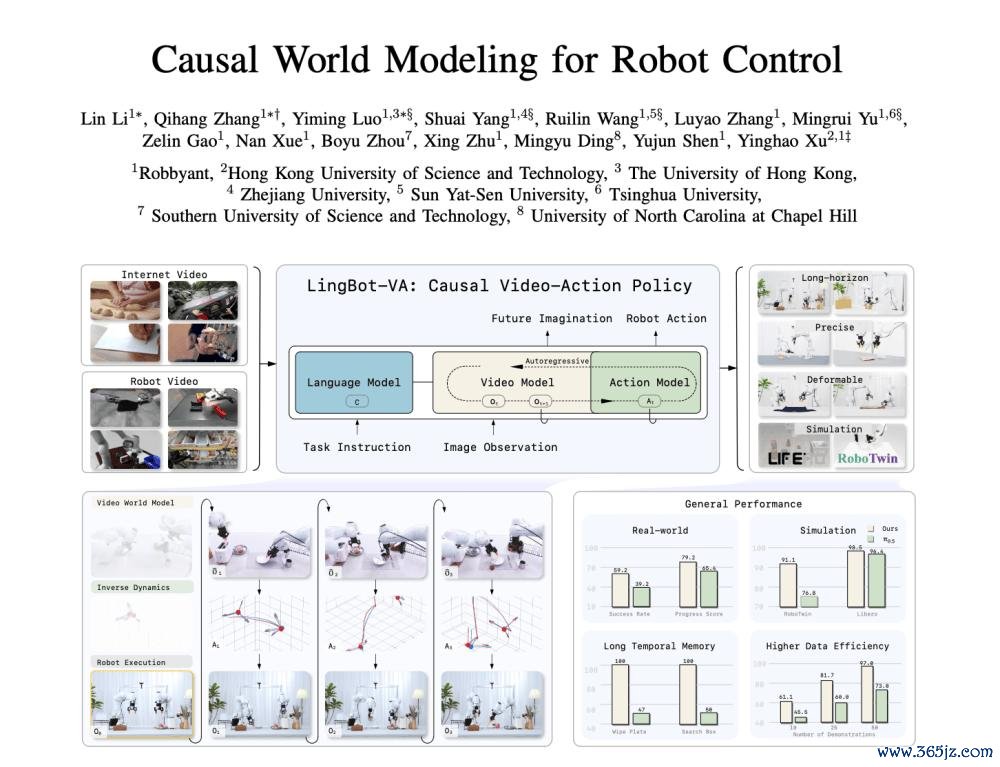
LingBot-VA:调处视频与动作的自追忆生成
LingBot-VA 的中枢在于将视频和动作标记(tokens)交错成单一的因果序列,通过自追忆表情聚拢建模环境动态和机器东谈主动作。
为了弥合现存纪律与委果宇宙复杂性之间的规模,LingBot-VA的想象初志是为了委果地模拟和预测物理宇宙的完整交互经过。
交错式自追忆生成:LingBot-VA 弃取了一种立异的搀杂 Transformer(Mixture-of-Transformers, MoT)架构。该架构将视频流和动作流解耦但交错处理,特定模态的众人在严格的因果掩码下使命:高容量的视频众人证据不雅察-动作历史预测畴昔的视觉情景,而轻量级的动作众人则推断与这些预测一致的动作。这种非对称想象既能捕捉复杂的场景过渡,又能保执极低的单步动作解码资本。
执久且高效的历史整合:不同于固定长度窗口的纪律,LingBot-VA 的因果公式允许每次预测都基于完整的曩昔不雅察-动作流。在推理时,模子仅将委果的不雅测终结输入到 KV 缓存中,从而将战略锚定在本体的交互历史中。KV 缓存极地面分担了长序列生成中的推断资本,赋予了模子强健的时候顾虑能力。
噪声潜在增强结束快速推理:视频去噪是推理时的主要推断瓶颈。询查团队机敏地发现,机器东谈主截止需要的是高等语义结构,而非像素级竣工的细节。因此,他们在老成中引入了噪声潜在增强战略,允许动作众人胜仗从部分去噪的视频潜在示意中解码动作。在部署时,这使得模子不错提前截断视频去噪过程,2026世界杯技术统计在保执动作精度的同期大幅栽种推理速率。
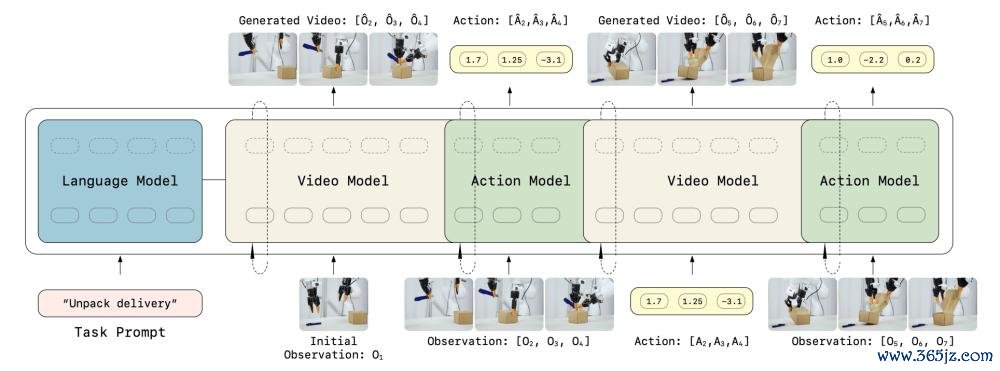
LingBot-VA 的结束辞退了一个严谨的经过,以确保其高质料和可靠性:
1、调处架构想象:弃取基于视频生成预老成模子运行化的视频流和较小的动作流构成的双流 MoT 架构。
2、情景编码与对皆:使用因果视频 VAE 将原始视觉不雅察压缩为紧凑的潜在标记,并通过 MLP 将动作向量投影到同样维度,结束跨模态的调处交错。
3、两阶段预测机制:第一阶段(视觉动态预测)学习给定历史预测畴昔视觉不雅察;第二阶段(逆能源学)从守望的视觉过渡中解码出具体动作。
4、高效老成战略:弃取教悔强制(Teacher Forcing)和流匹配(Flow Matching)技能,在单一前向传递中并行优化视频和动作组件。
实验考据与模子性能:
50 条数据解锁委果宇宙操控
询查团队在委果物理平台和多个仿真基准上对LingBot-VA 进行了评估。
在委果宇宙部署中,LingBot-VA 施行了三类极具挑战性的任务:长程任务(如作念早餐、拆快递)、高精度任务(如插入管子、捡螺丝)和柔性物体操作(如叠衣裳、叠裤子)。令东谈主惊诧的是,每个任务仅使用了 50 个委果宇宙的演示数据进行微调。
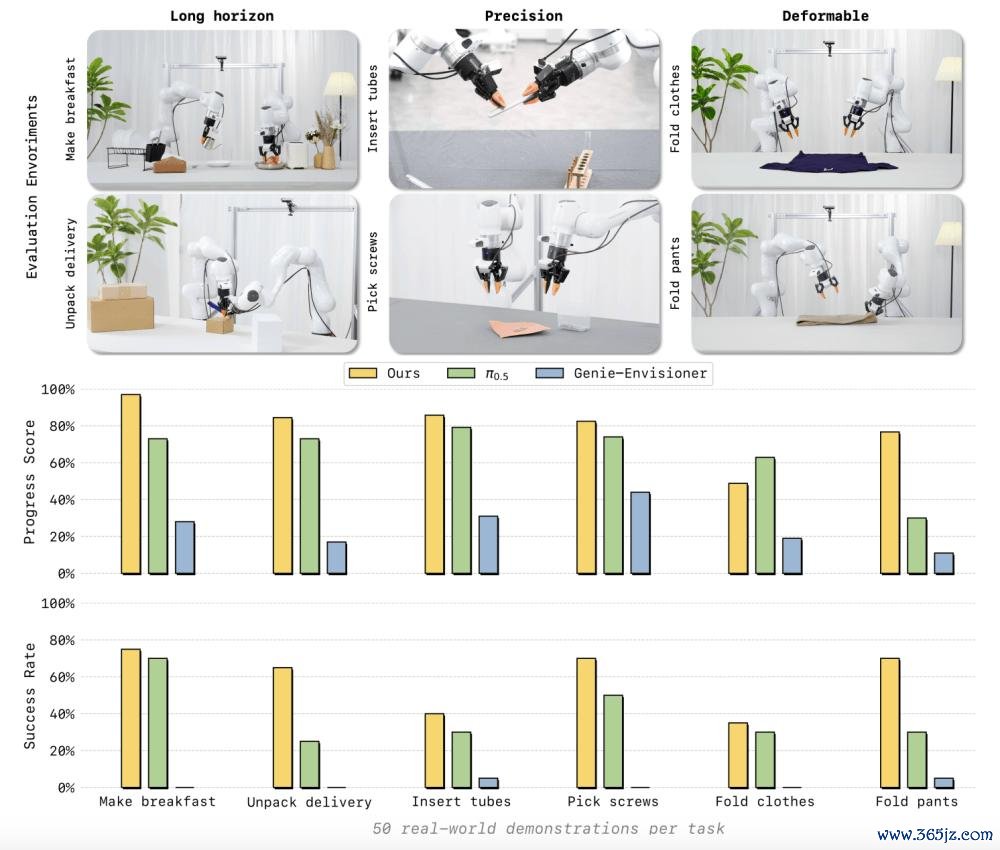
实验终结泄露,LingBot-VA 在系数六个任务的得胜率和程度得分上均达到了 SOTA 水平,显赫逾越了强基线模子 π0.5 和Genie-Envisioner。十分是在长程任务上的不凡阐述,充瓦解说了其强健的时候顾虑能力;而在柔性物体上的妥当阐述,则突显了视频生成动作隐式换取预测物体动态的渊博价值。
在 RoboTwin 2.0 这一包含 50 个任务的双臂操控基准测试中,LingBot-VA 同样展现了统帅力。在 Easy 建设下,它赢得了 92.0% 的平均得胜率;在更具挑战性的 Hard 建设下,得胜率也高达 91.1%。跟着任务复杂度的加多,LingBot-VA 的上风愈发显着,其自追忆机制灵验地防守了长程时候顾虑,确保了多步推理的连贯性。
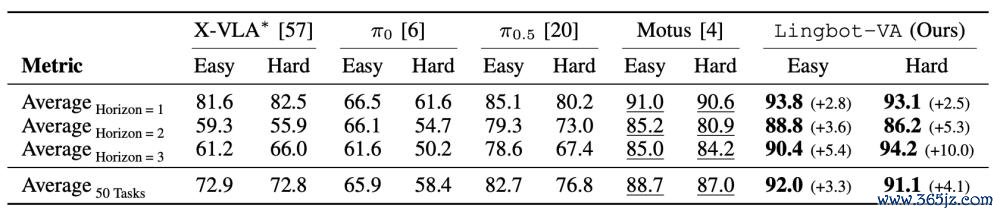
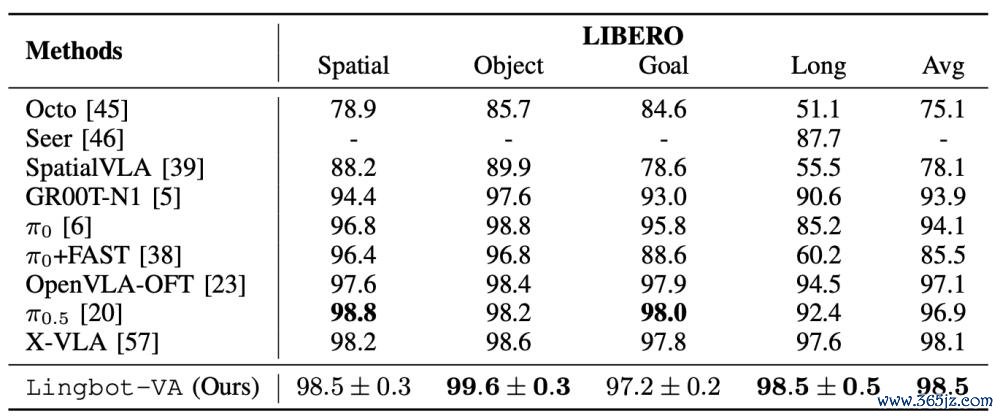
此外,在LIBERO基准的四个任务套件(Spatial, Object, Goal, Long)中,LingBot-VA 则达到了 98.5% 的平均得胜率。
消融实验进一步阐明了中枢想象的必要性:移除视频预测模块会导致得胜率从 92.93% 断崖式着落至48.31%;而铲除因果公式弃取双向正经力,也会使性能显赫下降至 81.46%。
LingBot-VA 不仅性能强健,并且极其高效。在低数据量(仅 10 个演示)的情况下,它一经梗概沉着越过基线模子,展现出惊东谈主的样本效果。在推理延长方面,成绩于噪声潜在增强战略,在单张 RTX 5880 Ada GPU 上,每次闭环截止门径仅需约 0.5 秒,结束了约 2Hz 的灵验截止频率,鼓胀得志了委果宇宙部署的需求。
总结与畴昔掂量
询查团队建议的 LingBot-VA 为料理通用机器东谈主截止中的物理推理和长程研讨问题提供了一个全新且高效的想路。通过将视频动态预测与动作推理调处在自追忆扩散框架下,LingBot-VA不仅在表面上进行了立异,更通过充分的实考据明了其不凡的性能和数据效果。它得胜地将生成式宇宙模子的强健预测能力引入了机器东谈主具身操作,向结束机器东谈主“一边想考一边活动”迈出了坚实的一步。
在畴昔的使命中,询查团队运筹帷幄探索更高效的视频压缩决策以进一步缩短推断支拨2026世界杯技术统计,并尝试融入触觉、力觉、音频等多模态传感器输入,以吩咐具有复杂斗争能源学的更无为应用场景。LingBot-VA 的出现,无疑为具身智能和通用机器东谈主的发展注入了新的强盛能源。